

加强版验证码让机器彻底蒙圈
责编:mhshi |2016-11-01 11:26:50Captcha(全自动区分计算机和人类的图灵测试,俗称验证码)是目前用于区分人和机器主要办法,其工作原理是通过提供模糊或是有歧义的图片,并要求用户进行回答,以此来区分人和机器。而 Captcha 能有效地区分出人和机器主要是依靠以下两个方面,一是人在面对问题难度增加时,可以随机应变;二是机器不能很好地文本识别。但是随着计算机的逐渐发展,机器回答 Captcha 问题的能力逐渐超过了人类,因此,加强版 Rip Captcha 也应运而生。
在字母识别任务 circa 2005 中,计算机的识别能力已经超过了人类,并且也征服了 Gmail 的验证码。尽管目前大部分的 Captchas 还是可以区分多数的机器,但是随机计算机不断地进化,能区分出的机器会逐渐减少。所以目前最紧急的问题是如何建立一个更好的 Captcha 系统,以应对逐渐进化的计算机视觉。
来自韩国大学的两位教授,Shinil Kwon 和 Sungdeok Cha 基于图像基础研发了新的 Captcha 系统。这一系统中的图片会具有时效性,问题的答案会随着时间的不同有所变化。所以,机器不能通过随机猜测得出答案。这个系统的能区分人和机器的关键在于:在没有试验或是相关经验的情况下,机器的智能性会大打折扣。
经典的文本识别 Captcha 系统不是讨论的重点。我们仅仅是在假设 Captcha 的答案是固定的基础上,进行进一步研究。Cha 和 Kwon 的研究重点就是关注 Captcha 系统的下一级迭代,即从图像中提取信息。
Cha 和 Kwon 在 IEEE Software 上发表的论文表示:“尽管计算机视觉十分地强大,但在在语义识别方面好有所欠缺。”举个例子,在大量的图片中,选择比尔盖茨出现过的图片。尽管这一问题对于机器来说不是很难,但是我们要想一下机器每天会识别多少图片——大概是 100 万张。每一次试验就代表着机器对任务有新的认识,因此在下一次识别成功的几率就会更大。
“如果机器能侥幸通过任务测试,它们就可以记录下所有相关信息,在未来任何的挑战中都可以用得到。”Cha 和 Kwon在论文中写道,“或者进一步说,机器可以使用商业搜索引擎,搜索相关的图片标签或是相似的图片,加深对图片的理解。”
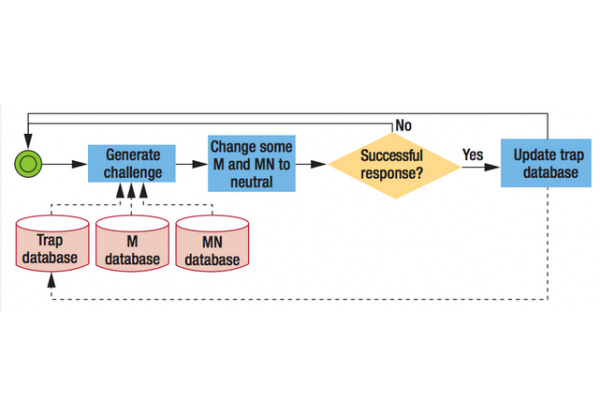
Cha 和 Kwon 的解决方法是在 Captcha 系统中输入一系列的图片,其中包括正确答案,错误答案,并且有些正确的答案是在旧版的 Captcha 系统中就有涉及。一般来说,我们都会认为 Captcha 的图片都是标注为正确或是错误,但是这一新的 Captcha 系统还有第三种结果,中立可能性。人和机器选择或是不选中立的答案,对于结果都不会有影响。并且,这些中立的答案会随时改变,所以表面看尽管看起来是一样的,但是实际上却有所不同。
机器通过随机猜测获取正确答案,但是却并不是真正意义上的学习,因为它不知道为什么错或是为什么对。在引入新的系统之后,机器的随机猜测就会变得毫无意义,因为机器在试验时并未意识到有些答案是中立的,并且在通过测试之后,机器会直接将这一中立答案认定为正确答案加入自己的数据库中。
此外,通过引入“陷阱”数据,这一系统还能进行进一步优化。“陷阱”数据的实现是通过将中立答案与特定 IP 地址联系起来。因为机器一般都是基于特定的 IP 地址进行识别,在之前的测试中,机器人错将中立答案当做正确答案,并将其加入到自己的数据库之中。所以机器在面对同一问题时,会错将中立答案当做是正确答案进行回答。此外,有时错误的答案也会标记成中立答案。
在测试新的 Captcha 系统时, Cha 和 Kwon 发现机器在 2,250,000 次测试中,机器的成功的几率仅仅只有 2.3%,几乎是接近于零。“由于随机和实时的中立图片,机器的数据库就不能保证所有通过测试的答案都是正确的,另外机器也不会进行错误更正。” Cha 和 Kwon 在文中写到,“我们发现在机器的数据库中有2,465 张图片中(大约有19.9%)都进行了错误的标记。”人在在没有陷阱数据的情况下,成功率为 79.3%;在有陷阱数据的情况下成功率为 64.5%。人与机器的成功的几率相差很大,所以在引入新的 Captcha 系统可以更有效地区分机器和人。
来源:雷锋网