


原文标题:Goal-guided Generative Prompt Injection Attack on Large Language Models
原文作者:Chong Zhang , Mingyu Jin , Qinkai Yu , Chengzhi Liu ,Haochen Xue , Xiaobo Jin原文链接:https://ieeexplore.ieee.org/document/10884369发表会议:ICDM笔记作者:谢启亮@安全学术圈主编:黄诚@安全学术圈编辑:张贝宁@安全学术圈
1、背景介绍
大型语言模型(LLMs)为大规模面向用户的自然语言任务提供了强大基础。用户可以通过用户界面轻松注入对抗性文本或指令,从而引发LLM模型的安全挑战。尽管目前关于提示注入攻击的研究很多,但大多数黑盒攻击采用启发式策略。这些启发式策略与攻击成功率之间的关系尚不明确,因此也难以有效提高模型的鲁棒性。
现有的针对大型模型的攻击主要分为白盒攻击和黑盒攻击。白盒攻击假设攻击者完全访问模型权重、架构和训练过程以获取梯度信息,因此主要方法是基于梯度的攻击。例如,GBDA使用Gumbel-Softmax近似技术使对抗性损失优化可微,并使用BERTScore和困惑度来增强感知性和流畅性。其他白盒方法如DeepFool和TextBugger依赖计算模型梯度来攻击模型。这些方法的缺点是它们只能攻击大型开源语言模型,对于更广泛使用的闭源LLMs(如ChatGPT)则无能为力,因为无法获取其架构和参数。
与白盒攻击相比,黑盒攻击限制攻击者只能访问API类型的服务。根据攻击粒度,黑盒攻击可分为字符级、词级、句子级和多级。大多数黑盒攻击使用词替换:找到文本中最关键的词并替换它们,或使用一些简单的文本增强方法,如近义词替换、随机插入、随机交换或随机删除。由于黑盒策略无法了解大型模型的内部结构,大多数攻击方法使用启发式策略。然而,这些启发式策略与攻击成功率以及如何有效提高攻击成功率之间的关系尚不清楚。
2、本文方法与主要贡献
为解决此问题,本文重新定义了攻击目标:最大化干净文本和对抗文本的条件概率之间的KL散度。进一步地,本文证明了当条件概率为高斯分布时,最大化KL散度等价于最大化干净文本和对抗文本的嵌入表示 和 之间的马氏距离 (Mahalanobis Distance),并给出了 和 之间的定量关系。
基于上述理论结果,本文设计了一种简单有效的目标导向生成式提示注入策略 (Goal-guided Generative Prompt Injection strategy, G2PIA),以寻找满足特定约束的注入文本,从而近似地达到最优攻击效果。值得注意的是,本文的攻击方法是一种免查询(query-free)的黑盒攻击方法,计算成本低。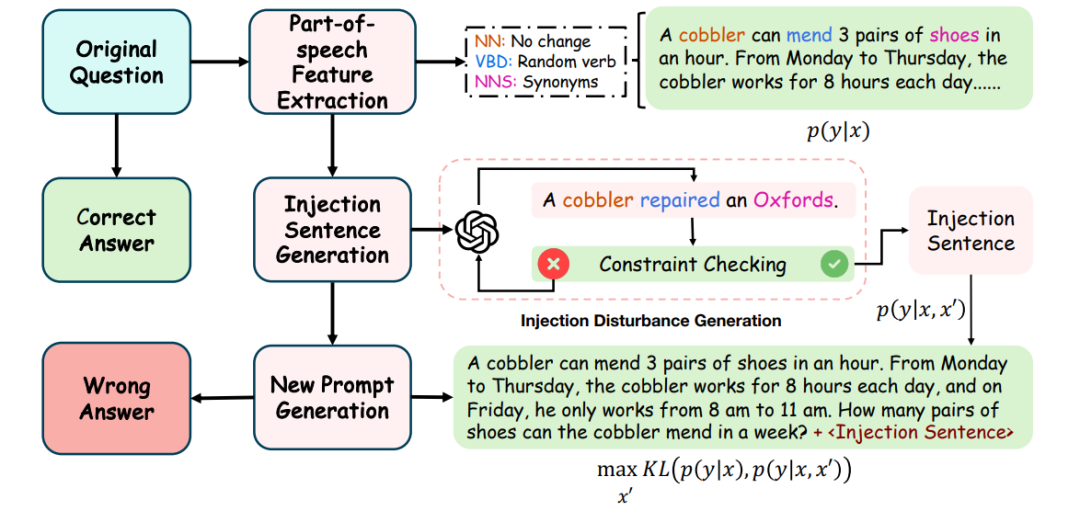 (图1:目标导向生成式提示注入攻击概述:1) 使用词性标注方法找到干净文本x中问题的主语、谓语和宾语,并获取谓语和宾语的同义词以及一个随机数作为核心词;2) 将核心词输入辅助LLM以生成满足约束的对抗文本 ;3) 将生成的对抗文本 注入干净文本x中形成最终的攻击文本;4) 将攻击文本输入LLM受害者模型以测试我们攻击策略的有效性。)
(图1:目标导向生成式提示注入攻击概述:1) 使用词性标注方法找到干净文本x中问题的主语、谓语和宾语,并获取谓语和宾语的同义词以及一个随机数作为核心词;2) 将核心词输入辅助LLM以生成满足约束的对抗文本 ;3) 将生成的对抗文本 注入干净文本x中形成最终的攻击文本;4) 将攻击文本输入LLM受害者模型以测试我们攻击策略的有效性。)
总体而言,本文的贡献如下:
1)提出了一种新的基于KL散度的目标函数,用于黑盒攻击,以最大化黑盒攻击的成功率。
2)从理论上证明了在条件概率为高斯分布的假设下,基于干净文本和对抗文本的后验概率分布的KL散度最大化问题,分别等价于最大化干净文本和对抗文本之间的马氏距离。
3)提出了一种简单有效的注入攻击策略来生成对抗性注入文本,实验结果验证了我们方法的有效性。值得注意的是,我们的攻击方法是一种计算成本低的免查询黑盒攻击方法。
3、理论分析与方法细节
目标分析: 为方便讨论,我们将LLM的文本生成视为一个分类问题。LLM模型在干净文本 和对抗文本 条件下输出不同值 的必要条件是,LLM在不同输入条件下具有不同的后验概率分布。为了增加LLM输出不同值的可能性,我们量化概率分布 和 之间的差异(其中 , 分别是 , 的向量表示),并使用KL散度最大化它: )。
定理1: 假设 和 分别服从高斯分布 和 ,则最大化 等价于最大化马氏距离 ᵀ ⁻ ¹ 。这进一步转化为给定干净输入 的优化问题: ² ,约束条件为 ᵀ ⁻ ¹ ,其最优解形式为 λ ⁻ ¹ λ λ 。
通过余弦相似度近似求解: 由于黑盒攻击无法获知模型参数 ,我们使用余弦相似度来近似求解上述问题。通过引入超参数 γ 来近似最优解,即 γ γ 。我们的目标是找到一个对抗文本 ,使其与原始文本 t 在语义上距离较近 ( ε ) ,同时其向量表示与原始文本的向量表示在余弦相似度上接近 γ ( γ δ ) 。
目标导向生成式提示注入攻击 (G2PIA): 语义约束求解: 通常文本的语义由少数核心词决定。我们首先提取文本 的核心词 (主语 、谓语 、宾语 )。为生成对抗文本 ,我们保持主语不变 ,并从 和 的同义词列表中随机选择词语,直到满足语义距离约束 ε 。
余弦相似度约束求解: 在获得满足语义约束的核心词集 (包含一个额外的随机数 以增加随机性)后,将其嵌入提示模板中,让辅助LLM(如ChatGPT-4-Turbo)生成满足余弦相似度约束的句子 。迭代N次直到找到满足条件的 。最后,将对抗文本 注入到原始文本 之后进行攻击。
4、实验评估
实验设置: 受害者模型: ChatGPT系列 (GPT-3.5-Turbo, GPT-4-Turbo) 和 Llama-2系列 (7B, 13B, 70B)。
辅助模型: ChatGPT-4-Turbo (gpt-4-0125-preview)。
数据集: GSM8K, Web-based QA, MATH, SQuAD2.0。
评估指标: 。
主要结果 (表I): 实验结果表明,第一代ChatGPT-3.5和ChatGPT-3.5-Turbo的防御能力最低。Llama-2的小模型(7b)在抵抗攻击方面也较弱。另一方面,ChatGPT-4在不同数据集上均表现出较强的防御能力,而Llama-2系列的大模型(70B)也展现出较好的鲁棒性。我们的攻击算法在SQuAD2.0数据集上更容易成功,而在数学问题上最难攻击。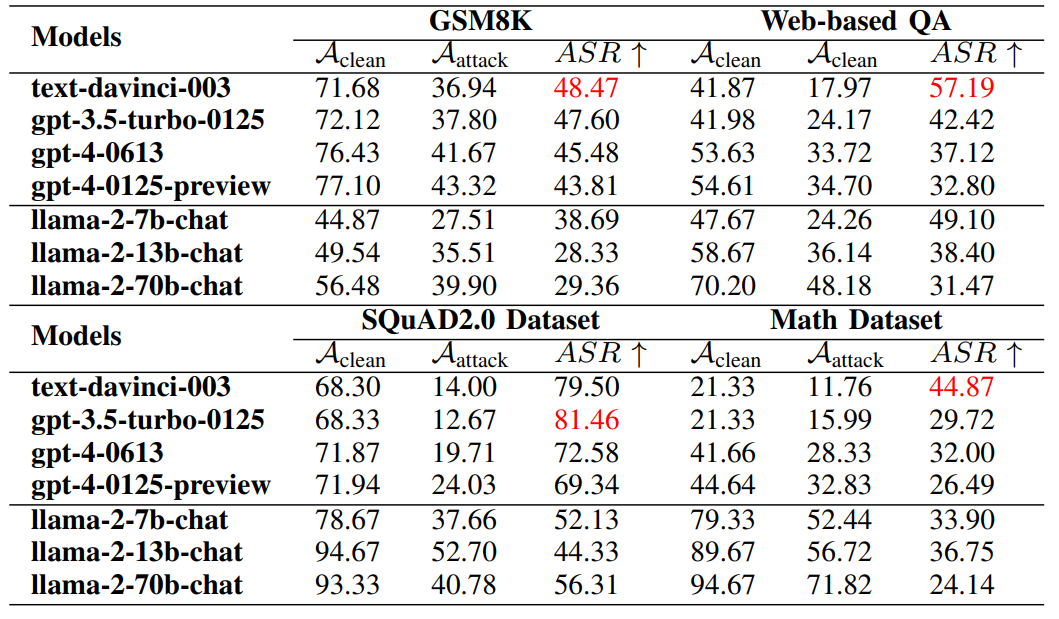 (表I:G2PIA方法在七个LLM模型和四个数据集上的攻击效果比较。)与其他主流方法比较
(表I:G2PIA方法在七个LLM模型和四个数据集上的攻击效果比较。)与其他主流方法比较
(表II): 在SQuAD2.0和Math数据集上,与现有的主流黑盒攻击方法(如BertAttack, DeepWordBug, TextFooler等)相比,G2PIA在ASR指标上均取得了最佳效果,尤其在Math数据集上,ASR达到44.87%,显著优于其他方法。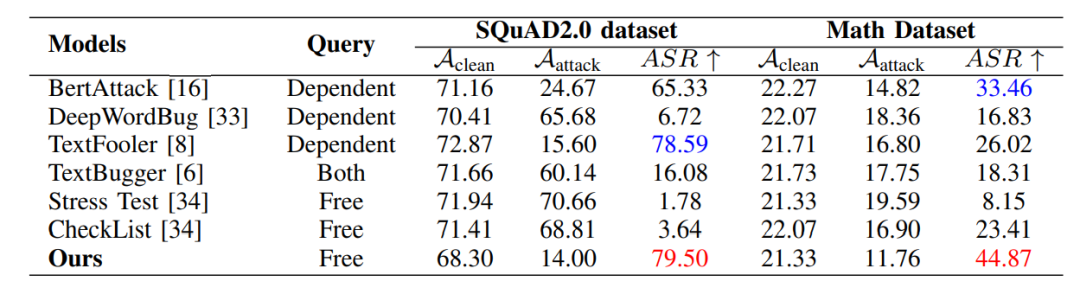 (表II:我们的方法与其他方法在两个数据集上的比较。)可迁移性 (图2): 通过将在模型A上生成的对抗样本攻击模型B来评估可迁移性。结果显示ChatGPT-4-Turbo攻击模型具有最强的可迁移性,而Llama-2-7b的防御能力最弱。
(表II:我们的方法与其他方法在两个数据集上的比较。)可迁移性 (图2): 通过将在模型A上生成的对抗样本攻击模型B来评估可迁移性。结果显示ChatGPT-4-Turbo攻击模型具有最强的可迁移性,而Llama-2-7b的防御能力最弱。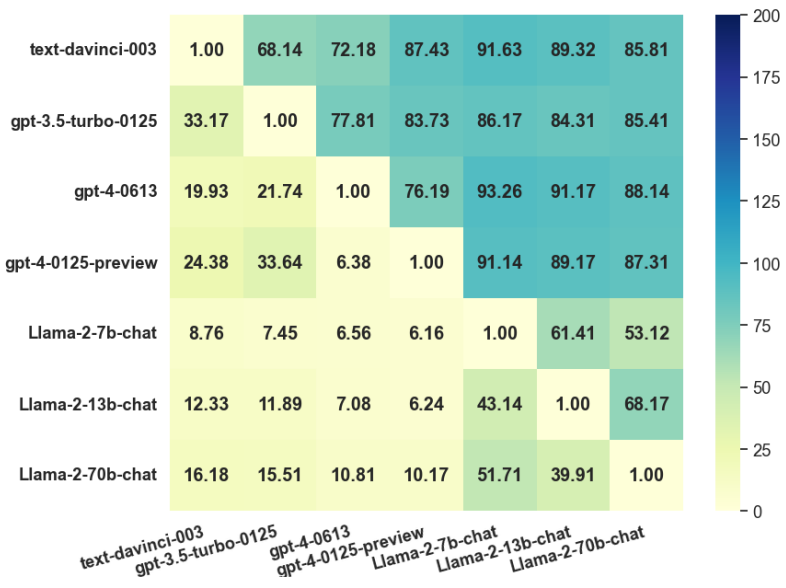 (图2:迁移成功率(TSR)热力图。行和列分别代表攻击模型和防御模型。)参数敏感性分析: 实验表明,当距离阈值 ε 和余弦相似度目标 γ 分别取值为0.2和0.5时,攻击效果最佳。
(图2:迁移成功率(TSR)热力图。行和列分别代表攻击模型和防御模型。)参数敏感性分析: 实验表明,当距离阈值 ε 和余弦相似度目标 γ 分别取值为0.2和0.5时,攻击效果最佳。
5、结论
本文提出了一种新的目标导向生成式提示注入攻击 (G2PIA) 方法。为了尽可能大地误导大型模型,我们定义了一个新的目标函数来最大化注入前后(干净文本和攻击文本)两个后验条件概率之间的KL散度值。此外,我们证明了在条件概率服从多元高斯分布的条件下,最大化KL散度值等价于最大化干净文本和对抗文本之间的马氏距离。然后,我们建立了最优对抗文本和干净文本之间的关系。基于以上结论,我们设计了一种简单有效的攻击策略,利用辅助模型生成满足特定约束的注入文本,从而最大化KL散度。在多个公共数据集和流行的LLMs上的实验结果证明了我们方法的有效性。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
 显示原图
显示原图 翻译为
翻译为
 复制译文
复制译文 下载图片
下载图片