

前言
作为安全研究人员的基本功之一,我们通过分析程序所有的系统API调用就能大致知道程序的作用,或者至少可以知道程序是正常程序还是恶意软件。
因为系统API调用的序列反映出来是软件特定的行为顺序,这可以作为检测恶意软件的依据,所以检测程序是否恶意的关键是要找到一种合适的方法来处理API调用的顺序。
在深度学习中有一种方法称为LSTM对于处理时序数据非常有效,本文就是基于LSTM来进行检测。本文会详细介绍样本获取及特征、标签的处理流程,LSTM的原理并通过实战展示如何应用AI技术检测windows恶意软件。
LSTM
LSTM是一种特殊的 RNN,能够学习长期依赖性。由 Hochreiter 和 Schmidhuber(1997)提出的,并且在接下来的工作中被许多人改进和推广。LSTM 在各种各样的问题上表现非常出色,现在被广泛使用。它被明确设计用来避免长期依赖性问题。
所有RNN都具有神经网络的链式重复模块。在标准的 RNN 中,这个重复模块具有非常简单的结构,例如只有单个 tanh 层,如下所示
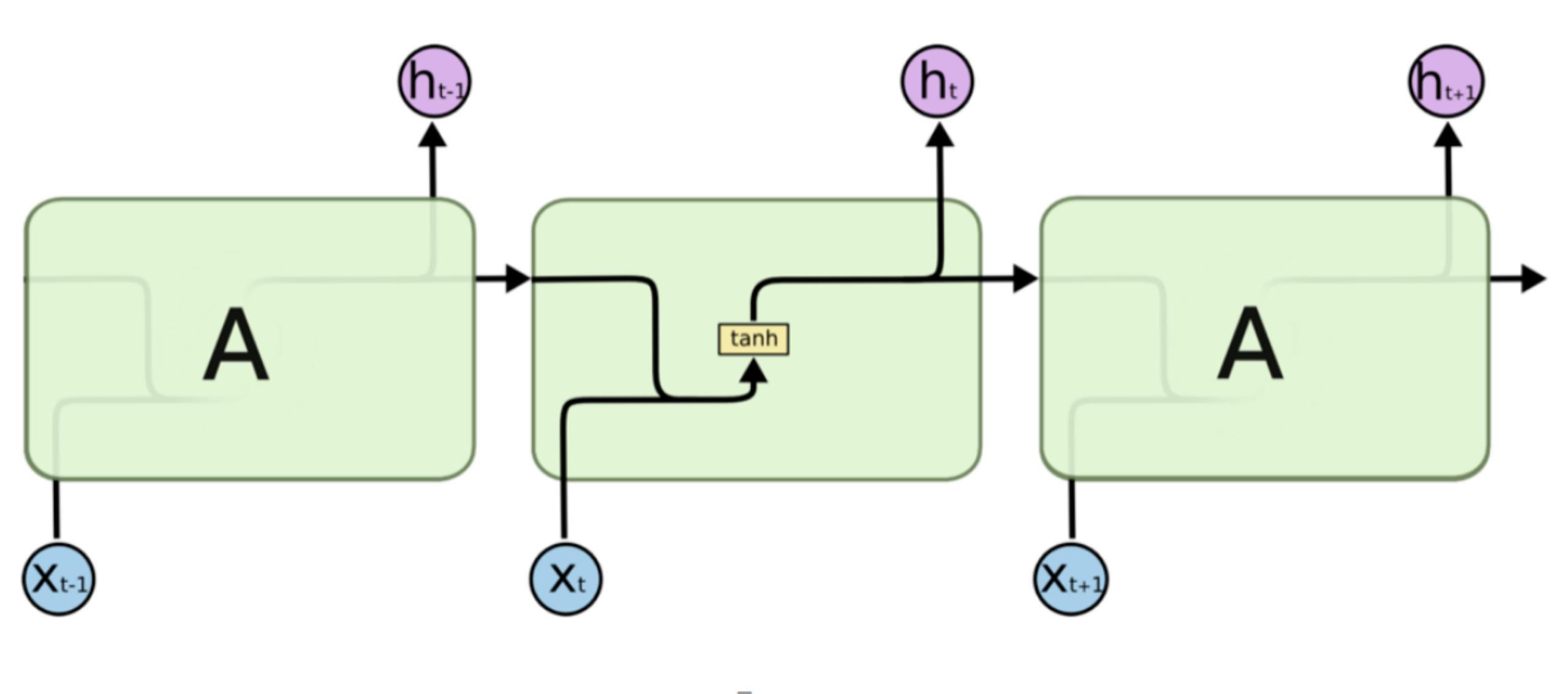
作为一种特殊的RNN,LSTM 也具有这种类似的链式结构,但重复模块具有不同的结构。不是一个单独的神经网络层,而是四个,并且以非常特殊的方式进行交互。
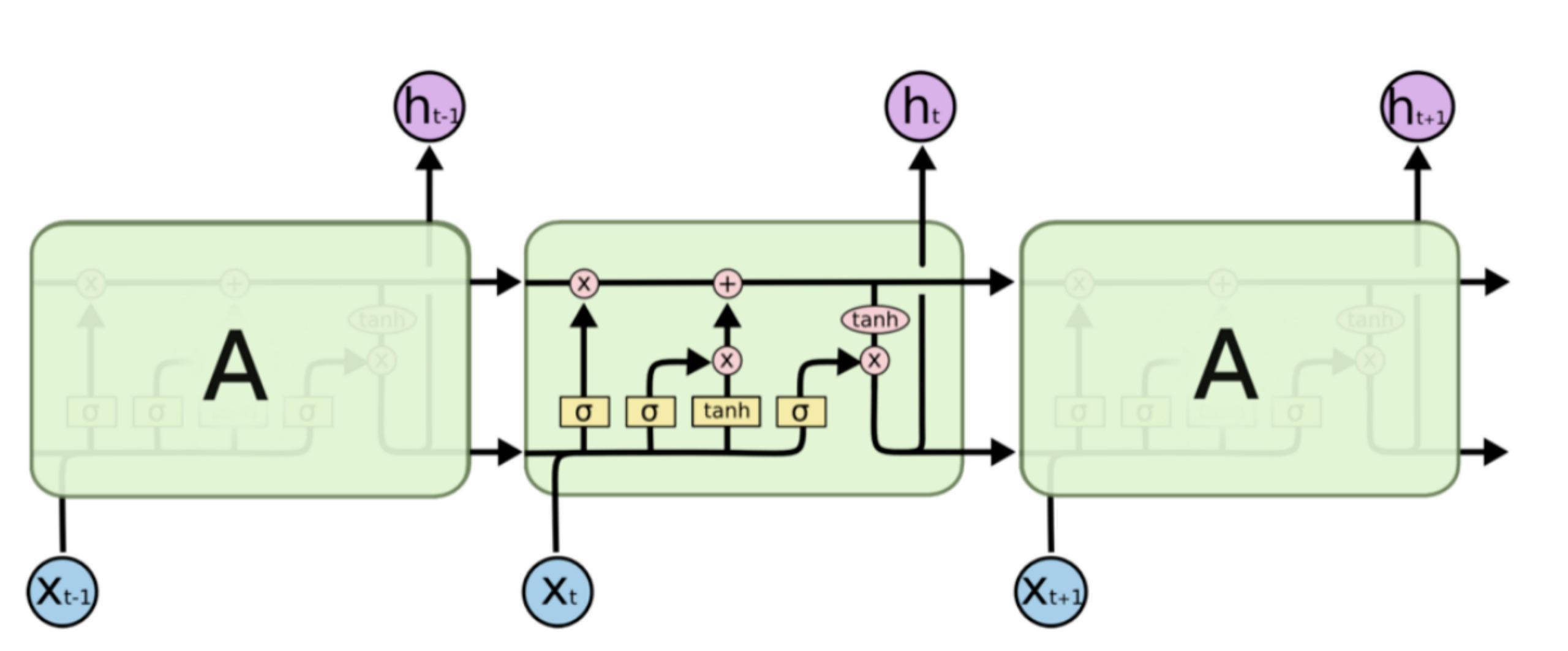
把上图中的重要标记拿出来

图中黄色类似于CNN里的激活函数操作,粉色圆圈表示点操作,单箭头表示数据流向,箭头合并表示向量的合并(concat)操作,箭头分叉表示向量的拷贝操作。
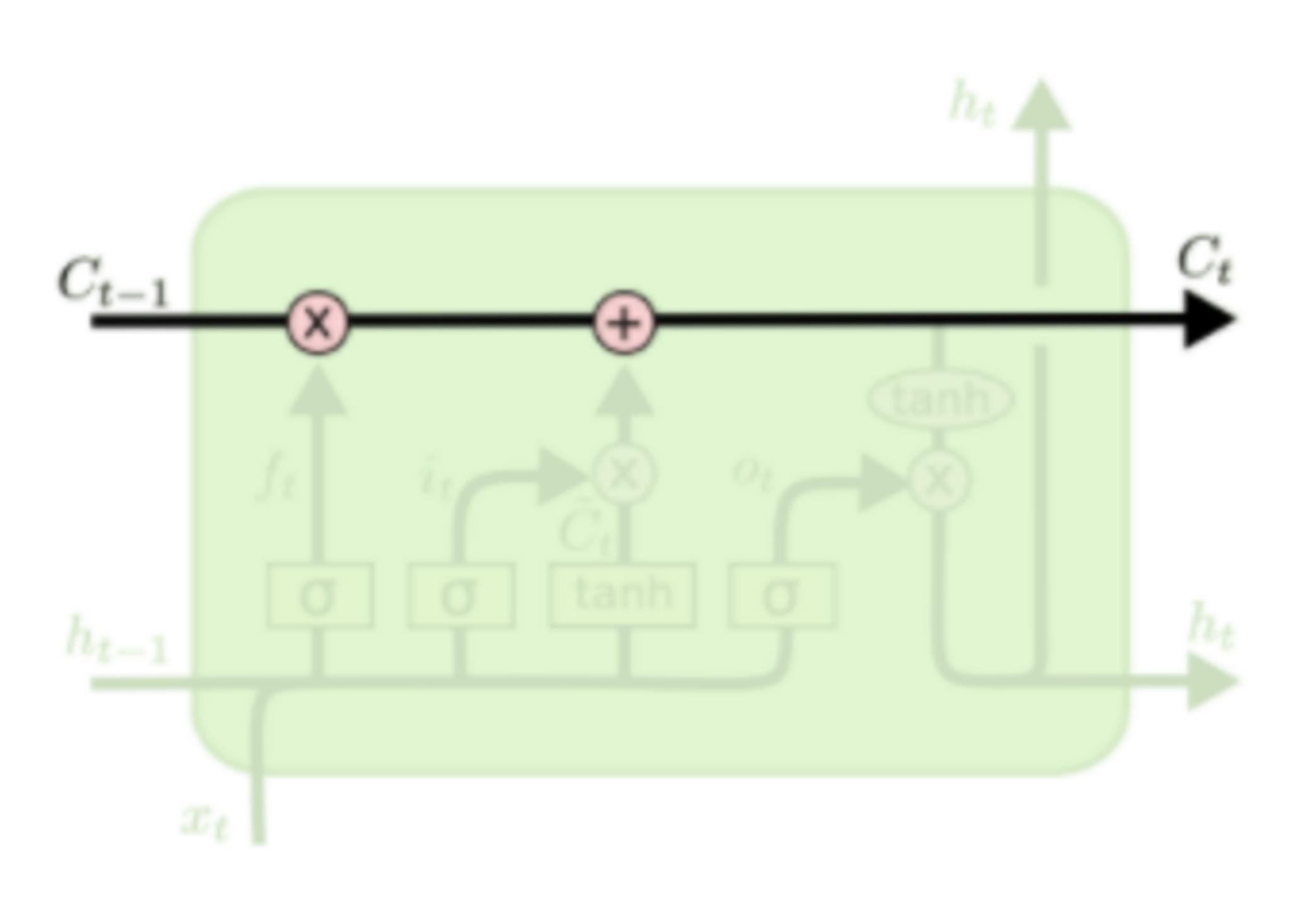
LSTM结构的关键是细胞状态,用贯穿细胞的水平线表示。
细胞状态像传送带一样。它贯穿整个细胞却只有很少的分支,这样能保证信息不变的流过整个RNNs。细胞状态如下图所示
LSTM网络能通过一种被称为门的结构对细胞状态进行删除或者添加信息。门能够有选择性的决定让哪些信息通过。其实门的结构很简单,就是一个sigmoid层和一个点乘操作的组合。如下图所示
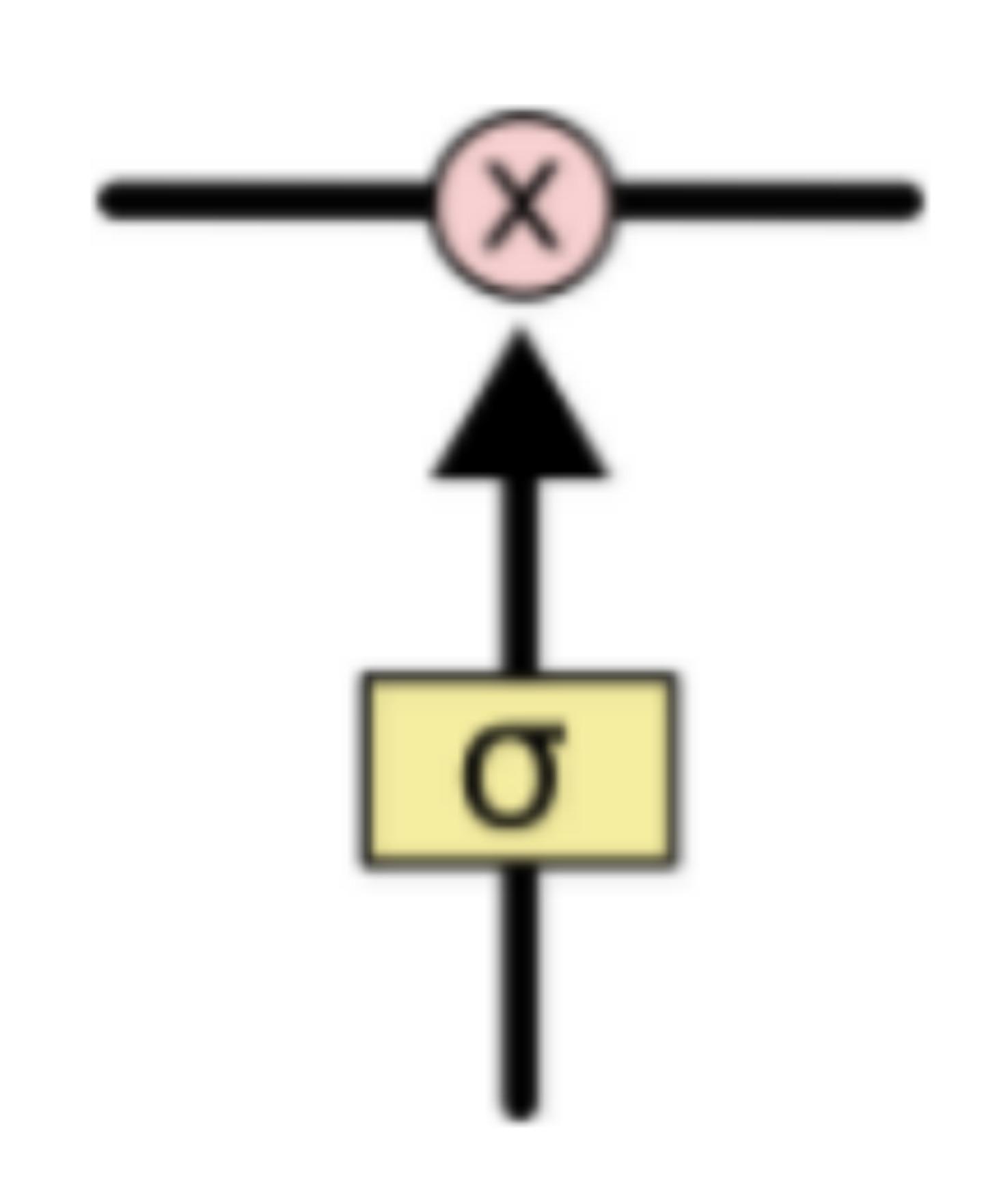
因为sigmoid层的输出是0-1的值,这代表有多少信息能够流过sigmoid层。0表示都不能通过,1表示都能通过。
一个LSTM里面包含三个门来控制细胞状态,这三个门分别称为忘记门、输入门和输出门。
LSTM的第一步就是决定细胞状态需要丢弃哪些信息。这部分操作是通过一个称为忘记门的sigmoid单元来处理的。它通过查看ht-1和xt信息来输出一个0-1之间的向量,该向量里面的0-1值表示细胞状态Ct-1中的哪些信息保留或丢弃多少。0表示不保留,1表示都保留。忘记门如下图所示。
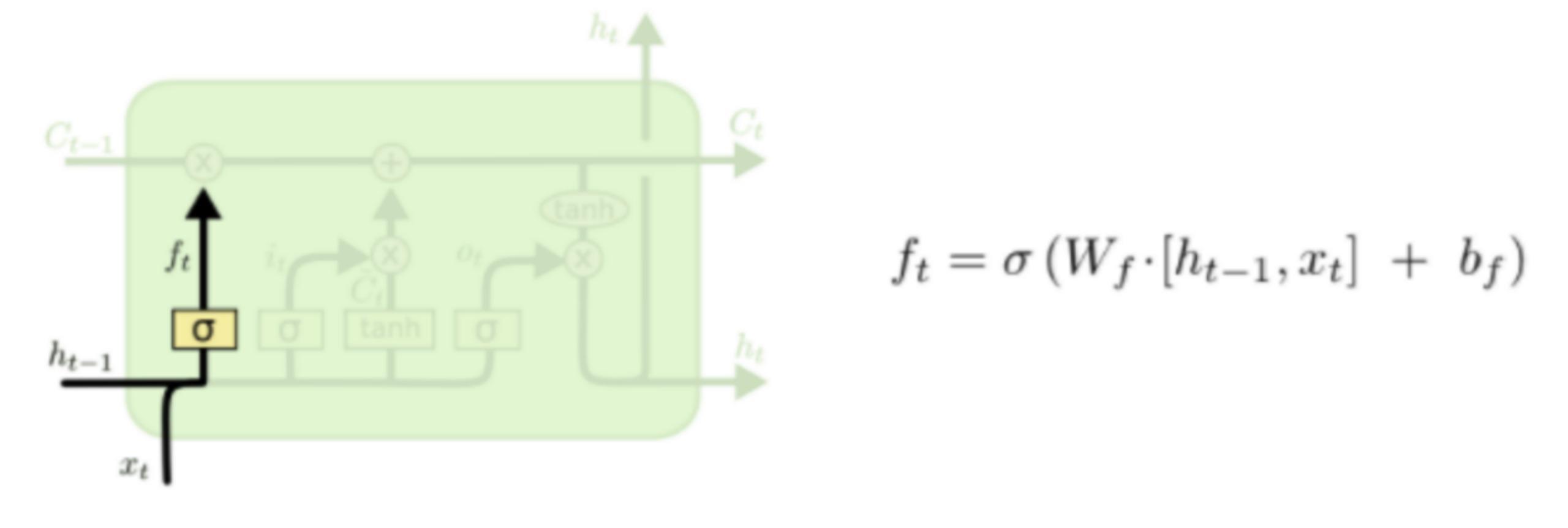
比如我们试图拥有所有的语句来预测下一个单词,cell状态可以包括当前主题任务的性别,这样我们在下一句话输出时就能准确的使用代词“他”,“她”还是“它”!
下一步是决定给细胞状态添加哪些新的信息。这一步又分为两个步骤,首先,利用ht-1和xt通过一个称为输入门的操作来决定更新哪些信息。然后利用ht-1和xt通过一个tanh层得到新的候选细胞信息C~t,这些信息可能会被更新到细胞信息中。这两步描述如下图所示。
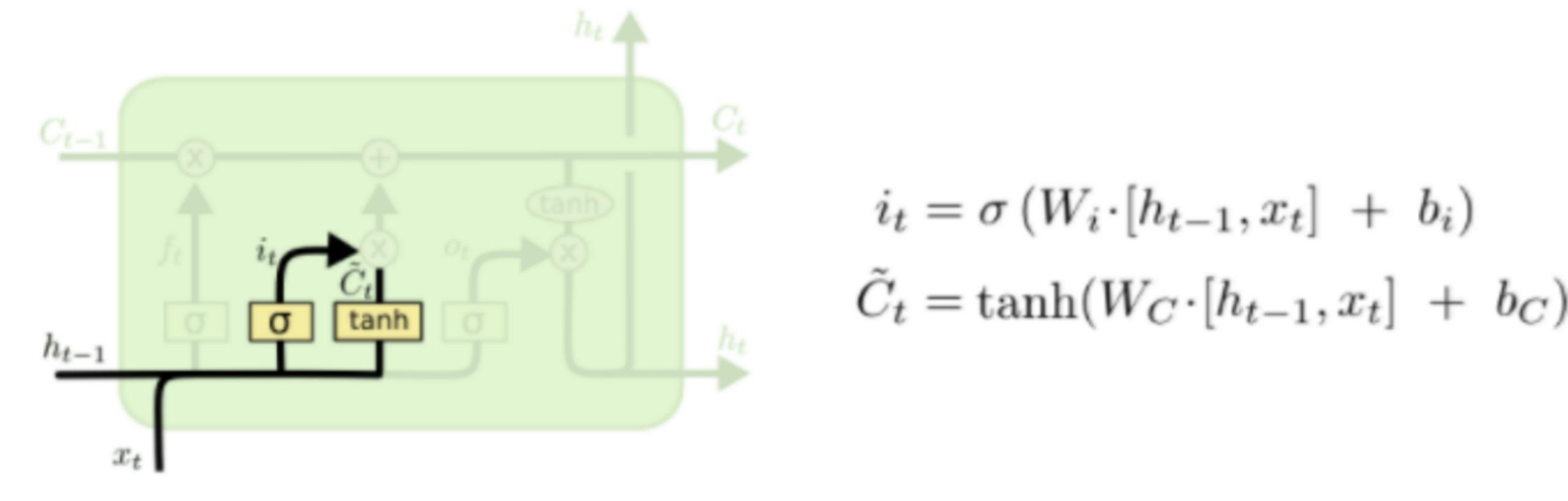
下面将更新旧的细胞信息Ct-1,变为新的细胞信息Ct。更新的规则就是通过忘记门选择忘记旧细胞信息的一部分,通过输入门选择添加候选细胞信息C~t的一部分得到新的细胞信息Ct。更新操作如下图所示
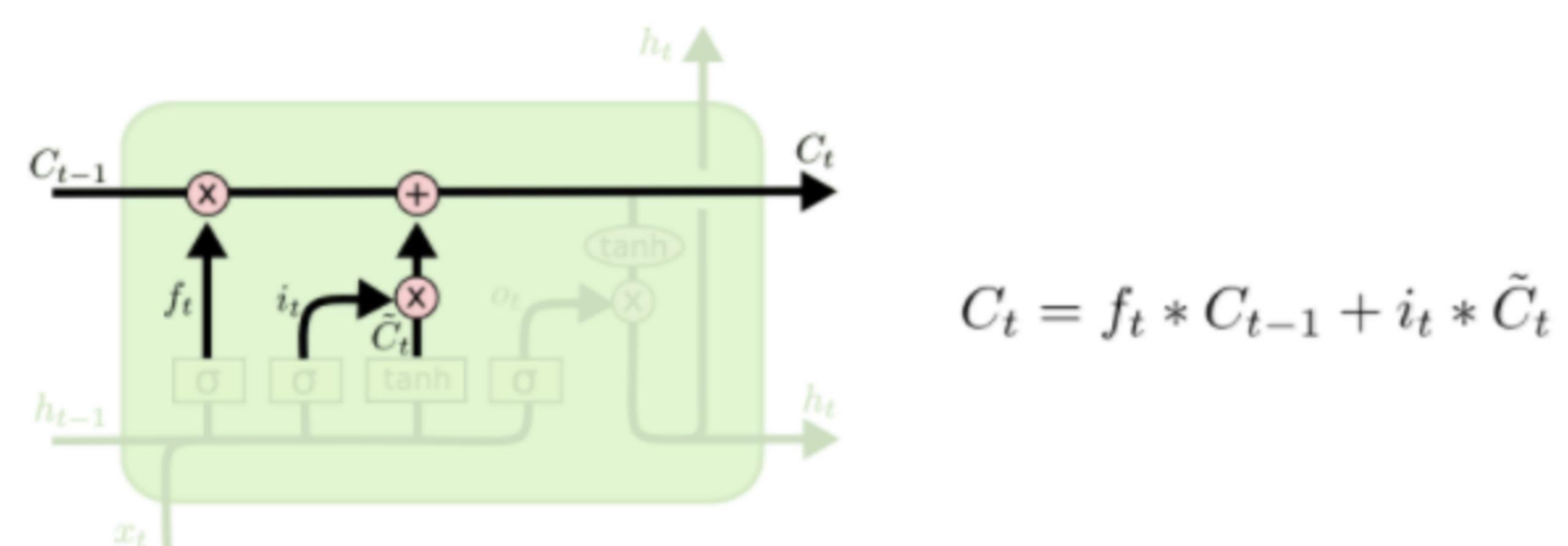
更新完细胞状态后需要根据输入的ht-1和xt来判断输出细胞的哪些状态特征,这里需要将输入经过一个称为输出门的sigmoid层得到判断条件,然后将细胞状态经过tanh层得到一个-1~1之间值的向量,该向量与输出门得到的判断条件相乘就得到了最终该RNN单元的输出。该步骤如下图所示
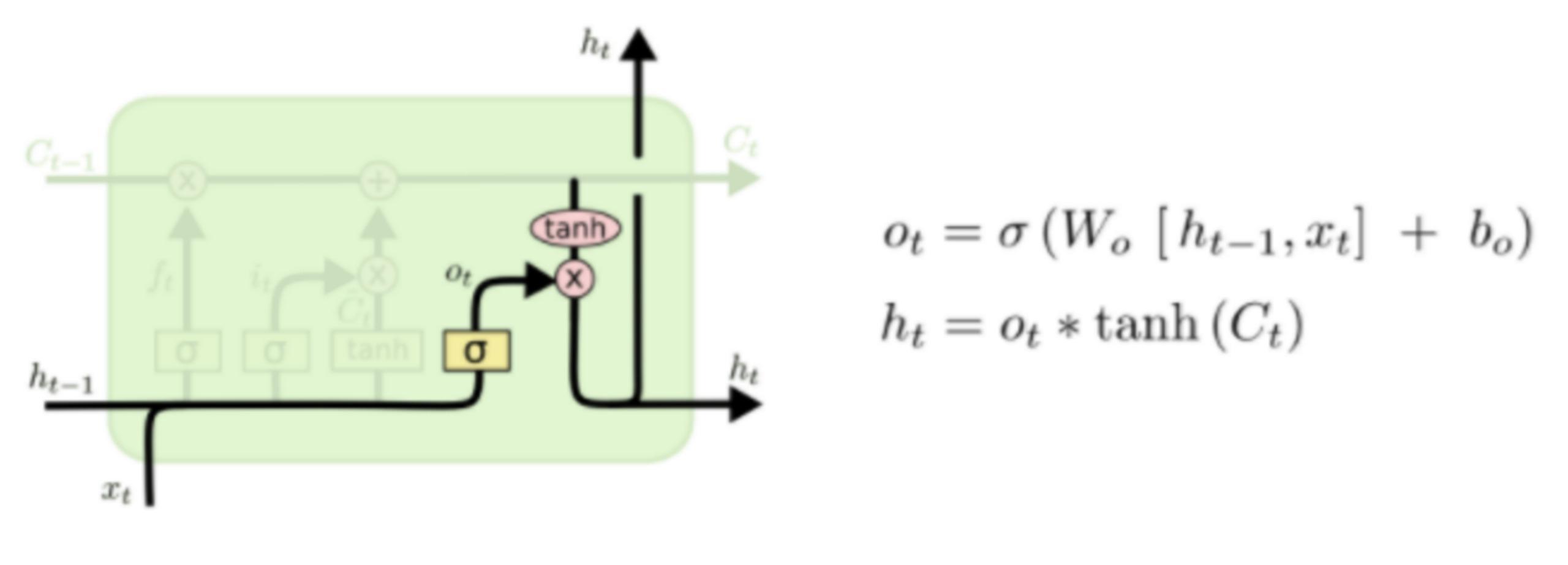
实战
整体流程如下所示
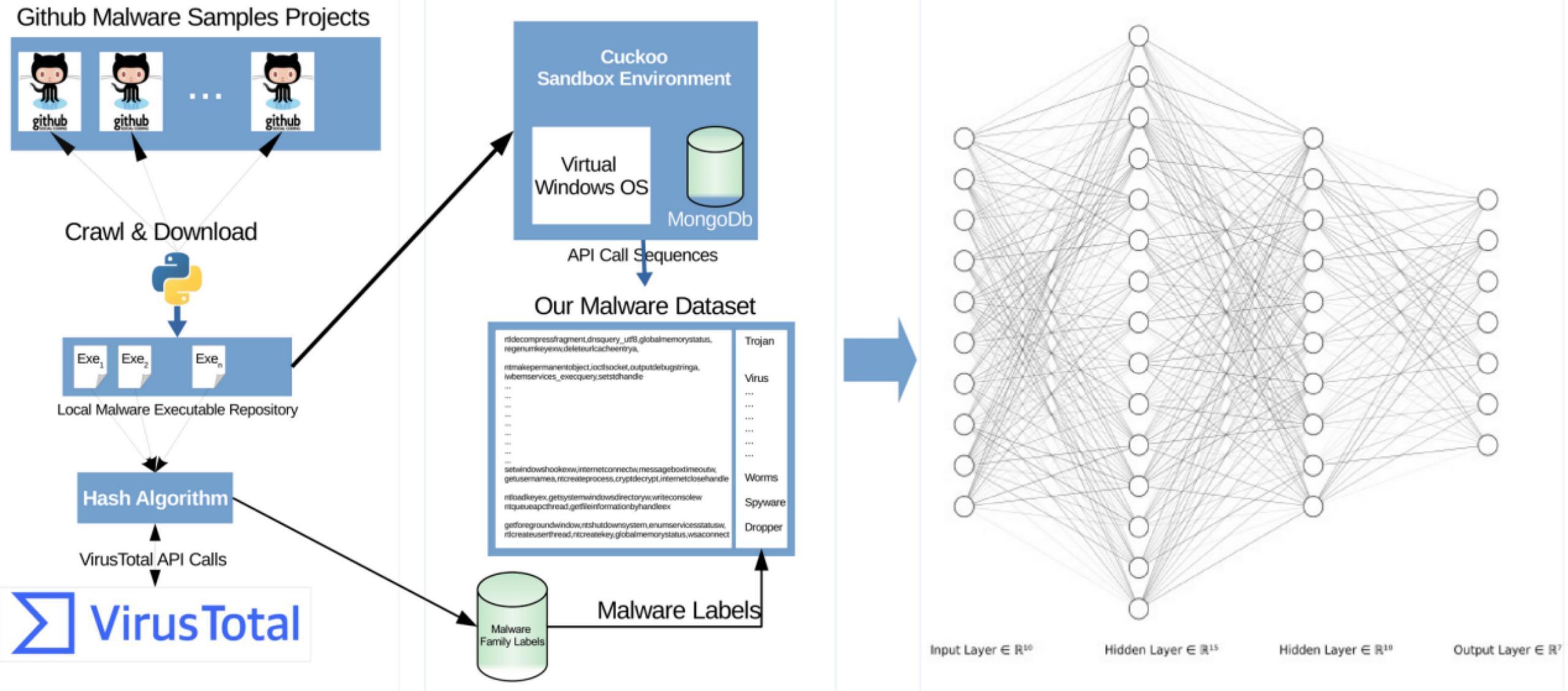
构建数据集
从AI的角度看,AI的三个要素是数据集、模型、算力。需要我们做的就是数据集和模型两部分。首先是数据集的部分,我们需要创建相关的数据集。如同我们之前提到的,我们需要创建window pe恶意软件的API调用序列数据集。
我们首先从github爬取或者下载样本文件,一方面用VirusTotal Service检测,用于给样本打标签,一方面将样本提交到Cuckoo Sandbox获取恶意软件的windows API调用序列,处理完成后就得到了实验所需的数据集。
这一部分比较简单,属于数据预处理的环节,我们直接看处理后得到的结果。
通过Cuckoo Sandbox获取恶意软件的windows API调用序列如下所示

通过VirusTotal Service检测得到的结果如下所示
数据集有了,接着我们开始搭建标准的LSTM模型来进行检测。
搭建模型
首先导入所需的库文件
将API调用序列以及分类结果合并在一起
最后一行相当于是将数据集划分成了两类,如果是Virus则打标签1,否则打标签为0
我们看看virus和非virus的分布情况
合并的数据集还不能直接输入给LSTM模型,目前这仅是一个文本语料库,我们需要将其向量化,创建一个基于tokenization的序列作为输入,这一步我们直接使用keras提供的keras.preprocessing.text.Tokenizer即可实现
下面的代码主要用到了fit_on_texts,这是为了基于API_calls列表更新内部vocabulary;texts_to_sequences则是为了将文本转为整数序列
然后搭建一个典型的LSTM模型
使用均方误差(mse作为损失函数,优化器用rmsprop,度量指标用accuracy)
开始训练
训练完毕
接着我们在测试集上进行测试,使用混淆矩阵来评估模型的性能
这个矩阵怎么看呢?对于二分类问题来说,左上角是真阳性TP,右上角是假阳性FP,左下角是假阴性FN,右下角是真阴性TN。从上面的矩阵看到,其TP,TN都挺高,说明模型训练得不错
总结:
本文使用的LSTM基于API调用序列进行恶意软件检测,如果师傅们有兴趣,在两方面都可以进一步做些不同的尝试,比如
1)模型选择方面,如果还是针对时序特征的话,可以试试其他的RNN比如GRU等
2)在特征选择方面除了API调用序列这种特征,其他可以考虑的序列特征还有汇编文件的指令序列,比如在本实验基础上我们可以用gdb等工具直接由二进制文件生成汇编文件,提取指令序列,如下所示
在这些序列上应用和实战中相同的处理流程即可
3)自己不愿意动手从二进制文件样本开始处理数据的话,可以尝试直接用微软在kaggle竞赛中放出来的,链接在这里:https://www.kaggle.com/c/malware-classification,数据中对于每个恶意样本,给出了两个文件,分别是.asm文件和.bytes文件
分别如下所示
4)除了上述特征外,还可以考虑以下特征:
Virtual Adress and Size of the IMAGE_DATA_DIRECTORY
OS Version
Import Adress Table Adress
Ressources Size
Number Of Sections (we should look into section names)
Linker Version
Size of Stack Reserve
DLL Characteristics
Export Table Size and Adress
Address of Entry Point
Image Base
Number Of Import DLL
Number Of Import Functions
Number Of Sections
等
当然,具体选择什么特征,得根据手头的样本、掌握的AI技术等具体情况而定。
参考
1.https://peerj.com/articles/cs-285/
2.https://colah.github.io/posts/2015-08-Understanding-LSTMs/
3.https://zhuanlan.zhihu.com/p/32085405
4.https://en.wikipedia.org/wiki/Long_short-term_memory
5.https://www.jianshu.com/p/95d5c461924c
6.http://www.bioinf.jku.at/publications/older/2604.pdf
7.https://github.com/omerbsezer/LSTM_RNN_Tutorials_with_Demo
8.https://github.com/jaungiers/LSTM-Neural-Network-for-Time-Series-Prediction