

生成式人工智能融入软件供应链安全效果评估
责编:gltian |2025-03-27 16:44:54基本信息
原文标题: Integrating Artificial Open Generative Artificial Intelligence into Software Supply Chain Security
原文作者: Vasileios Alevizos, George A. Papakostas, Akebu Simasiku, Dimitra Malliarou, Antonis Messinis, Sabrina Edralin, Clark Xu, Zongliang Yue
作者单位:
- Karolinska Institutet, Sweden
- Democritus University of Thrace, Greece
- Zambia University, Zambia
- IntelliSolutions, Greece
- HEDNO SA, Greece
- University of Illinois Urbana-Champaign, USA
- Mayo Clinic Artificial Intelligence & Discovery, USA
- Auburn University Harrison College of Pharmacy, USA
关键词: 大语言模型(LLM)、软件供应链安全(SSC)、漏洞检测
原文链接: https://arxiv.org/abs/2412.19088
开源代码: 暂无
论文要点
论文简介:随着新技术的不断涌现,人为错误也始终存在。软件供应链日益复杂且相互交织,服务的安全性对于确保产品的完整性、保护数据隐私以及维持运营的连续性而言已至关重要。在这项工作中,研究者针对有前景的开源大语言模型(LLMs)在两大主要软件安全挑战方面开展了实验:源代码语言错误和弃用代码,重点探究大语言模型取代依赖预定义规则和模式的传统静态和动态安全扫描工具的潜力。研究结果表明,尽管大语言模型得出了一些出乎意料的结果,但它们也面临着显著的局限性,尤其是在内存复杂性以及处理新的、不熟悉的数据模式方面。尽管存在这些挑战,研究者积极应用大语言模型,再结合广泛的安全数据库以及持续的更新,这有望加强软件供应链(SSC)流程,以抵御新出现的威胁。
研究目的:本研究的目标是评估开源 LLMs 在检测软件供应链漏洞方面的能力,并探索它们能否替代传统的基于规则和模式匹配的安全扫描工具。此外,研究还分析了 LLMs 处理复杂的安全模式的能力,试图揭示它们在增强软件安全方面的有效性及局限性。研究假设:如果能够合理地结合 LLMs 与传统方法,或许可以弥补 LLMs 在某些领域的不足,实现更优的安全检测效果。
引言
软件供应链安全(SCS)在当今数字化时代至关重要,因为它不仅关系到产品与服务的完整性,还直接影响数据隐私和交易的顺利进行。一旦供应链环节遭到攻击,不仅会导致操作中断、效率下降和经济损失,更可能造成知识产权泄露等严重后果。SCS 的挑战主要来自其复杂性,涵盖从原材料采购、制造、运输到分销和处置的全流程,虚拟和实体层面相互交织,使得每个环节都可能成为攻击目标。
在此背景下,人工智能,尤其是大语言模型(LLMs),逐渐成为提升供应链安全的新工具。它们能够处理海量数据、识别异常行为、预测潜在风险,并为决策提供智能支持。尤其在代码检测、漏洞识别、风险预警等方面,LLMs 展现出强大的能力。然而,现有的传统安全扫描工具大多依赖静态规则与预设模式,面对新型威胁时往往反应滞后。因此,探索将 LLMs 融入供应链安全防护体系,成为当前研究的关键方向。
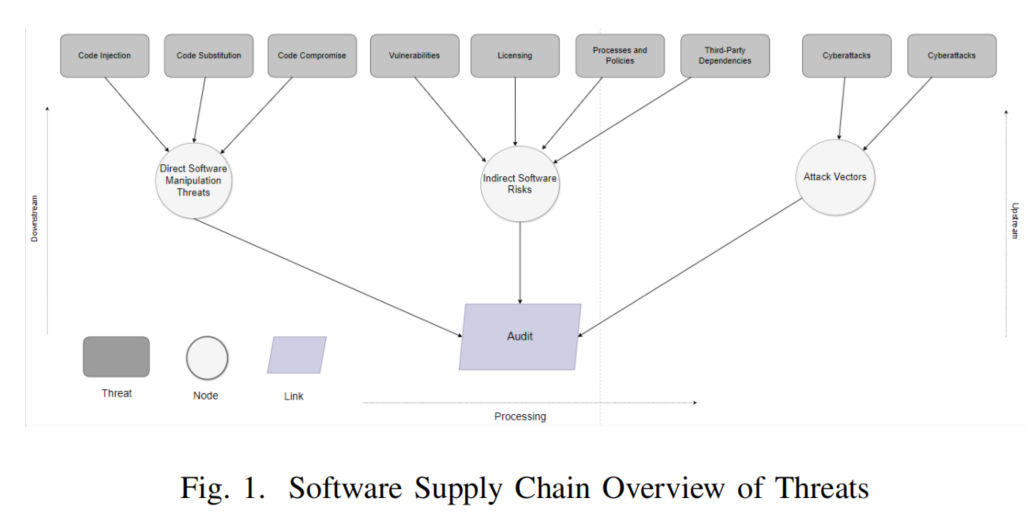
研究背景
近年来,大语言模型(LLMs)在识别和分析安全漏洞方面的应用受到广泛关注。尽管已有研究表明它们在漏洞检测中具有一定潜力,但模型鲁棒性、数据集偏差以及泛化能力等问题仍限制其在真实场景中的表现。例如,一些研究团队通过爬取网站数据,构建了如 DiverseVul 这类数据集,从开源项目中提取存在漏洞和非漏洞的源码,以提升模型训练的覆盖面。然而,仅仅扩大训练数据规模,并不能必然提高模型在实际漏洞检测中的效果。
部分研究还发现,基于 transformer 架构的模型(如 BERT)在特定语言(如 Java)上的漏洞分类任务中表现优异,准确率可达 99%、F1 值高达 94%。这些成果表明深度学习在特定任务上具有显著优势,但在泛化至复杂软件环境时仍面临诸多挑战。
此外,研究还指出,软件供应链安全不仅取决于技术手段,还受到第三方库质量、依赖关系、软件设计缺陷、恶意供应商行为等因素的影响。随着开源生态的广泛应用和代码复用的增多,攻击面迅速扩大,传统防御手段逐渐显得力不从心。因此,构建具备上下文理解能力和自我演化能力的智能检测模型,成为提升供应链安全防护能力的重要方向。
研究方法
本研究采用实验评估的方式,系统考察多个开源大语言模型(LLMs)在检测软件供应链漏洞和识别过时代码(deprecated code)方面的能力。实验以 TruthfulQA 基准测试作为评价工具,通过构造含有漏洞或代码错误的问题集,让模型作答,并由人工对其准确性和真实性进行评估,特别关注模型在处理复杂语义和模糊问题上的表现。
具体方法如下:研究团队对每组提示语(prompt)进行十轮测试,以确保结果的稳定性与代表性。实验运行在配备 GPU A100 的计算集群上,模型包括 OpenLLaMA、Gemma、Mistral-7B、GPT-2 和 Phi2 等。为公平比较,不同模型均接受相同任务评估,涵盖多种主流编程语言。
在数据集构建方面,研究者收集了多个编程语言中各自 500 个漏洞样本与过时代码模式,并进行了均衡划分,确保数据的代表性和广度。同时,研究还考虑了当前 LLMs 所面临的若干限制:例如上下文窗口长度受限,难以处理大型源代码文件;以及模型训练所依赖的数据来源不透明、能耗高昂等伦理问题。
通过上述实验流程,研究系统分析了各模型在不同语言环境下的检测表现,为评估 LLMs 在软件供应链安全中的实际应用潜力提供了数据支持。

论文结论
本研究强调,理解大语言模型(LLMs)的本质能力和局限性至关重要,包括其预期功能、训练数据领域以及已知的结构性缺陷。唯有在此基础上精心设计测试提示,才能确保评估结果的科学性与有效性。
研究发现,LLMs 在处理新信息时的记忆机制仍显薄弱,尤其在识别复杂或陌生的安全模式方面存在困难。此外,若在缺乏明确操作管道的前提下,直接使用开放式提示语,可能会导致模型生成被隐藏指令操控的恶意内容,从而引发新的安全风险。
尽管如此,这些挑战也揭示出未来研究的潜力方向:可以尝试从头构建或重新调整模型结构,并引入涵盖大量安全漏洞与“安全范式”的专业数据库,以提升模型对安全问题的敏感度和处理能力。与此同时,持续性的更新机制也将成为提升模型抗风险能力的关键。
研究还指出,在当前阶段,LLMs 更适合作为现有安全监测系统的补充工具。它们可以提供额外的一层智能分析,输出结构化、合理的安全建议,辅助安全团队做出更明智的决策。在人为操作错误频发的数字世界里,这类基于 AI 的协作手段有望提高整体软件供应链的韧性与安全水平。