

LLM-GUARD:基于大模型的C++和Python错误和安全漏洞的检测和修复
责编:gltian |2025-08-29 14:40:01基本信息
原文标题:LLM-GUARD: Large Language Model-Based Detection and Repair of Bugs and Security Vulnerabilities in C++ and Python
原文作者:Akshay Mhatre, Noujoud Nader, Patrick Diehl, Deepti Gupta
作者单位:
- 德克萨斯农工大学中部校区计算机信息系统系
- 路易斯安那州立大学超级计算与技术中心
- 路易斯安那州立大学物理与天文学系
- 洛斯阿拉莫斯国家实验室应用计算科学(CCS-7)
关键词:人工智能(AI)、大语言模型(LLMs)、代码审查、软件开发、安全性、漏洞检测、自动调试、C++、Python
原文链接:https://arxiv.org/pdf/2508.16419
开源代码:https://github.com/NoujoudNader/LLM-Bugs-Detection
论文要点
论文简介:本文针对当前大语言模型(LLMs)在代码审查与自动调试中的角色持续提升,但其在自动检测及修复C++和Python领域真实软件缺陷、特别是安全相关高级漏洞方面的实证能力尚未得到充分研究。作者以ChatGPT-4、Claude 3与LLaMA 4三种主流模型为对象,基于包含基础编程错误、典型安全漏洞及生产级高级Bug的综合公开数据集,系统评测了它们在多类型C++与Python代码缺陷上的表现。数据集涵盖了SEED Labs、OpenSSL(Suresoft GLaDOS)、PyBugHive等来源,均经本地编译与测试验证。
作者设计了多阶段、上下文感知的提示流程,真实模拟开发者调试场景,并采用分级评分表严格量化检测的准确性、推理深度及修复建议质量。实验显示,所有模型均能较好识别基础语法与语义错误,适合初学者教育和自动化代码初审,但在高级安全漏洞与复杂生产环境代码上的表现显著下滑。ChatGPT-4与Claude 3相较LLaMA 4能提供更细致的上下文分析。这一研究揭示了大语言模型在软件安全领域的潜力与局限,并为其实际应用边界提出了实证依据。
研究目的:当前LLMs已被广泛整合进软件开发流程,助力代码生成、调试及自动审查工作。然而,学界与业界关于这些模型在面向现实世界复杂C++和Python项目中的多样性缺陷,尤其是安全敏感漏洞的检测和修复效能,仍存在较大未知。论文意在系统性、量化地检验主流LLMs的实际能力。具体目标为:通过构建兼具编程初学者常见错误、典型安全漏洞、真实开源项目高阶缺陷的综合数据集,对ChatGPT-4、Claude 3、LLaMA 4三款代表性模型进行多维度评测,验证其在实际开发调试与安全审计中的有效性。同时,论文探索如何通过多轮、上下文增强提示设计,更真实地还原软件调试流程,并以分级评分标准量化不同模型的能力差异,为模型实际落地使用、安全可靠性评估及未来改进提供基础性实证支持。
研究贡献:
- 构建并发布了涵盖C++与Python语言、覆盖编程基础型错误、安全漏洞及生产级高级Bug的高质量公开基准数据集,所有样本均经本地编译和测试环节验证,确保问题的真实性和多样性。
- 设计并实现了新颖的多阶段、上下文感知型提示协议,真实模拟开发者实际调试和修复Bug的交互流程,为更科学合理地评价LLMs能力奠定基础。
- 对ChatGPT-4、Claude 3、LLaMA 4三款前沿大语言模型进行了系统对比、细粒度分析,统一基于严格分级评分标准量化其在Bug检测准确性、推理深度与修复建议等方面的表现,揭示了其优势、短板及实际适用场景,为大模型在代码质量保障领域的应用边界与未来改进提供实证参考。
引言
随着大语言模型(LLMs)在自然语言理解与生成领域的突破,诸如ChatGPT、Claude、GitHub Copilot、LLaMA和BERT等模型迅速成为软件开发场景中的主流工具。这些模型不仅能够将自然语言指令转换为代码,还能支持调试、自动答疑等各类代码相关任务,在集成开发环境(IDE)、教育平台和企业级DevOps流水线中被广泛应用,极大地提升了开发效率,降低了新手入门门槛。
尽管LLMs在助力代码生成和编程教育方面的潜能不断释放,学界和业界对于其在真实软件开发中的可靠性、特别是针对复杂、多样软件缺陷和安全漏洞检测能力的研究却相对滞后。而这一空白具有重大现实意义:未被检测的Bug会导致功能故障、安全漏洞,甚至给现代软件系统带来高昂的维护和安全风险。
本研究正是针对上述关键问题展开,提出全面、实证性的评测框架,专门分析ChatGPT-4、Claude 3(Sonnet 3.7)与LLaMA 4(maverick)等主流LLM在检测与分析各类C++与Python真实Bug方面的表现,覆盖从基础编程失误、经典安全漏洞到生产级项目中的高级缺陷。为确保严谨性,论文所用数据集包括SEED Labs与OpenSSL(通过Suresoft GLaDOS数据库)中的C++示例、以及PyBugHive收集的Python典型Bug,均经过本地编译测试验证。这些样本不仅反映了实验室场景下的易错点,还直接链接到实际生产环境下的高复杂度缺陷。
与以往仅依赖合成或窄范围样例的研究不同,作者的实验体系强调真实Bug验证,并通过多阶段、上下文感知的提示对LLMs进行多轮交互,最大程度还原真实开发者定位调试流程。同时,针对Bug检测的不同层次(如表层语法错误、深层语义漏洞与安全隐患),采用分级评分标准全面量化模型的检测准确率、推理深度及修复建议合理性。这种多维度评测方法,有助于揭示LLMs在静态和动态代码分析上的优劣势与适用边界。
该工作的新颖性在于首次提出多层次、情境感知的LLM能力评估框架,从表浅语法到深度语义、再到安全级别漏洞全方位检验,填补了从纯理论到实际工程领域的关键落差。与此同时,论文还关注了LLMs在自动化代码审查、教育辅助、甚至安全审计领域的应用前景,并系统揭示其局限性,为后续研究提供了路径和方法论。
相关工作与研究背景
近年来,利用大语言模型进行代码缺陷与安全漏洞检测已成为软件工程与安全社区的研究热点。已有工作探索了多种LLM及其衍生产品在多语言下的漏洞识别效能。例如,CodeQwen1.5、DeepSeek-Coder、CodeGemma、StarCoder-2、CodeLlama等模型在Python、Java、JavaScript等多种主流编程语言中进行过全面的漏洞检测能力比对;LProtector则将ChatGPT应用于C++代码自动审查;FuncVul结合LLM与函数级代码切块,以提升C/C++中安全缺陷的检测精准度。一些研究专门关注在实际开发社区如Stack Overflow上流传的易漏安全风险,测试主流LLM对真实代码片段的安全感知能力。此外,自动程序修复(APR)的研究也正借助LLM不断深化,诸如RepairAgent实现基于多智能体的Bug定位与修复,SRepair则侧重多函数复合型缺陷修复及成本效率提升。
尽管相关领域进展迅猛,现有研究大多面临两方面局限:一是多数评测样例过于合成化、脱离实际项目,难以揭示LLM在真实大规模生产环境中的检测与分析能力;二是缺乏对“深度推理+多轮交互”调试流程的模拟,难以评估模型在复杂场景下的推理、定位和修复真实力。另有文献综述系统梳理了LLM在代码安全与自动修复中的既有成就与瓶颈,但对大规模、全场景、全流程性评测仍有待补全。相较于上述工作,本文首次提出基于本地验证、生产级数据集和动态交互协议的全流程实证评测体系,具有现实可用性与方法创新的突出特点。
研究方法与评测流程
本研究制定了一套科学、严谨且具工程适用性的评测流程,全面检验三款主流LLM在多层级软件缺陷上的检测、推理与修复能力。
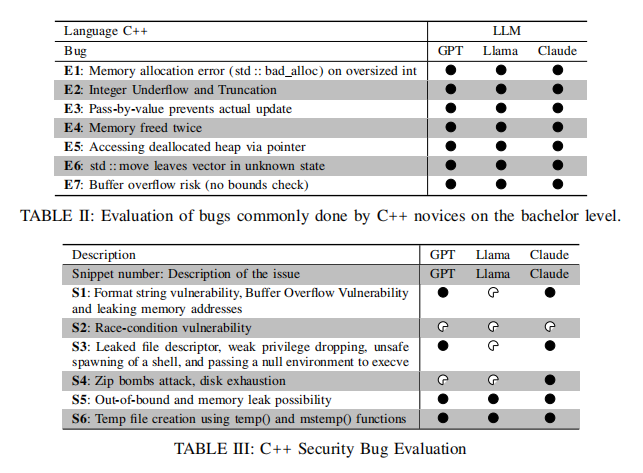
首先,论文构建了三大类数据集,覆盖不同复杂度与语境的真实Bug。其一为基础易错型Bug,包括如未初始化变量、错误参数传递、内存管理失误、逻辑漏洞、指针误用等典型初学者失误,主要来自大学编程课程常用教学案例。其二为C++安全漏洞样本,包含经典的竞态条件、格式化字符串漏洞、缓冲区溢出、不安全内存访问与提权路径等,突出安全红线与攻击面,由SEED Labs等安全教育平台提供。其三为高级生产级Bug,具体拆分为OpenSSL(Suresoft-GLaDOS数据库)内存安全、加密配置、类型推断等复杂C/C++缺陷,以及PyBugHive中NumPy、Pandas等主流Python开源库的API误用、边界行为、类型不匹配等代表性案例。每一项样本均要求本地编译(GCC 7.5/Python 3.7)或通过单元测试确认缺陷真实存在和可复现,保证原始数据质量与覆盖面
在与LLM的交互设计上,论文推行“多阶段上下文增强”提示机制。针对基础Bug,设计了“请您列出以下代码的所有编译期、运行期、逻辑错误及漏洞,并指明相关行数”的标准化最小提示,以评测模型对孤立代码的静态检测底线。对于高级Bug,进一步引入辅助上下文,如相关依赖文件片段、公共接口定义,模拟真实调试中开发者对周边语义的整合推理。例如对NumPy特定函数,结合实际单元测试用例交互递进,引导模型从现象到根因多步深入。这种动态、多回合提示策略不仅考查LLM的表层特征识别,更强调其跨文件、跨接口的上下文融合与推理适应能力。
在评估体系上,作者制定了分级可视化打分标准——从“未检测到Bug”到“完全检测并提出有效修复建议”分为五个档次(空心圆至实心圆),严格统计每一模型在每类Bug、每轮交互下的表现,以量化模型准确率、推理深度与修复建议质量。这种设计兼顾了过程性、细粒度刻画与最终效果输出的统一,非常适合为自动化工具或安全审计场景提供决策参考。
各类型软件缺陷检测实验与结果
全文对三类典型Bug的检测能力差异做了细致、系统的实验分析。
在基础C++ Bug检测方面,所有LLMs在静态、孤立代码环境下均表现出色。以未受界定的随机分配导致的std::bad_alloc为例,各模型均成功识别内存超限风险并给出边界校验建议。在传值阻断引用效果、双重删除、使用无效指针、std::move误用、空指针解引用、缓冲区溢出等常见陷阱上,三模型不仅准确标注了Bug位置,更能提出现代C++惯用的修复方式(如智能指针替换、引用传参优化)。这充分证明,当前主流LLM已可胜任初学者课程静态分析及教学反馈任务。
针对C++安全漏洞,LLMs的能力展现出明显分化。格式化字符串与缓冲区溢出(S1)、临时文件竞态条件(S2)、环境变量污染与Shell注入(S3)、空指针解引用(S4)、Zip炸弹资源耗尽(S5)、越界访问和内存泄漏(S6)、不安全临时文件名创建(S7)等实际攻击面场景下,ChatGPT-4与Claude 3常能发现主干违规及潜在链式攻击向量(如符号链接攻击、特权边界等),修复建议也更具操作性。而LLaMA 4虽能捕获大部分显性安全点,却在细微但关键的上下文风险(如文件描述符未关闭、特权管理等)上有所遗漏,推理链路偏向泛化、缺乏系统性说明。整体来看,顶级模型在安全攻防路径的洞察和推理能力上已具备辅助分析师审核的可用性,但尚未达到完全替代人工级别。
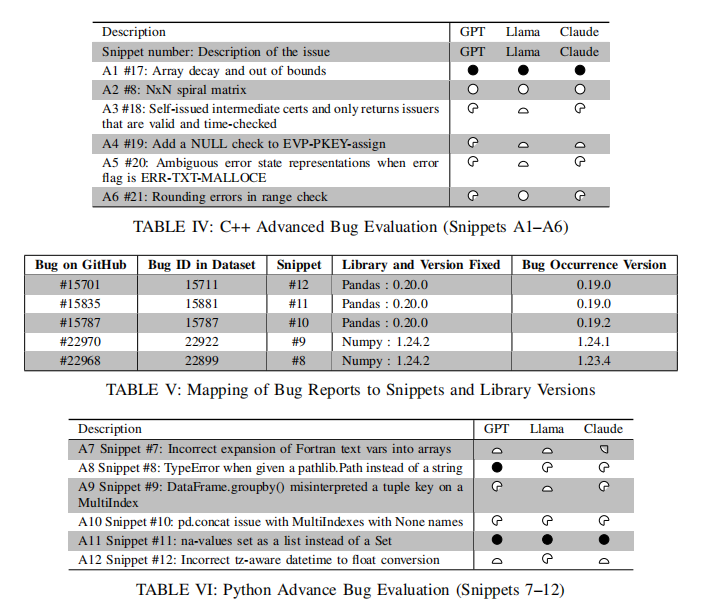
对于OpenSSL等真实生产库复杂Bug,LLM表现受限更为明显。例如数组衰减导致尺寸信息丢失(A1),ChatGPT-4、Claude 3、LLaMA 4均能识别调用语境与指针隐式转换风险,提出更安全API接口建议。证书验证有效期逻辑、加密API空指针未校验、错误标志滥用导致异常丢失、超大整数精度损失导致范围校验失效等高阶Bug场景下,顶级模型可准确定位原始逻辑误区与API约束缺陷,并给到防御性编程建议,但在极少数创新型“算法边界/矩阵布局”Bug检测(如螺旋矩阵复杂索引)时,全部模型的一次性修复能力尚有较大提升空间。
在Python主流库的微妙API兼容性和高阶逻辑错误识别方面,ChatGPT-4和Claude 3普遍表现突出,对类型不匹配(如pathlib.Path与字符串互转)、多层索引语义歧义、特殊场景下NaN处理、时区数据类型转换等根因及修复建议的把握远超LLaMA 4,体现了对高阶数据处理上下文的更高认知能力。
综上,三款主流LLM均已具备教育级、初级静态审查的可靠性,但在实际项目级安全漏洞、复杂逻辑及API契约判定等环节,只有顶级模型在综合推理与具体措施建议方面取得较好平衡。相关表格与详细数据充分量化了上述能力梯度,为模型选型和场景适配决策提供了翔实依据。
性能评估与分析
论文特别引入了COCOMO(Constructive Cost Model)等量化指标,估算各代码片段开发复杂度与模型检测难度的对应关系。针对Easy类别C++代码,无论开发工期(ESE)高低,三模型均能全量识别、精准修复。对于安全类别代码,模型能力与代码复杂度间出现明显相关性——复杂性提升时,除顶级模型仍可逼近完全检测,普通模型(如LLaMA)在高复杂度场景下的检测能力呈现瓶颈,仅能覆盖部分低复杂度的典型漏洞。对于高级C++和Python生产级Bug,无论模型层级,完全检测修复率均有所下降,只有ChatGPT-4和Claude 3在某些中等复杂度场景能够输出接近人工的诊断和修复建议。
论文进一步通过实验曲线和表格量化了不同Bug类型、不同比对模型在检测定位、推理深度、修复建议等多维指标上的综合表现。分析认为,LLMs在高复杂度环境下能力降级主要受限于跨模块上下文整合、API契约隐式推理和边界案例归纳等方面,对复杂场景广度和深度的自然语义编码能力仍是模型实际应用于高级安全与生产调试的核心挑战。
通过多轮回合和高维上下文补充后,主流LLM表现可显著提升,但横向对比显示,顶级模型的多维深度推理和修复建议稳定性表现出明显优势,尤其在安全审计、工业代码静态分析等关键场景更具现实应用价值。
论文结论
本研究首次从迭代、真实、多维度的实证视角,系统评价了主流大语言模型在跨复杂层级C++与Python软件缺陷检测、推理与修复任务中的实际能力。结果回顾发现,LLMs在初级语法/语义错误和教学案例上表现优异,具备英语静态分析和教育反馈自动化极高潜力。对于安全漏洞、生产级复杂Bug,顶级模型(如ChatGPT-4与Claude 3)展现出相对较好的上下文分析和推理深度,但在某些关键安全场景或复杂算法型缺陷下,依然存在推理链条断裂、修复建议不准确等共性短板。
研究强调LLMs当前仍较难完全胜任高级安全审计或复杂工程代码全自动修复,但已可作为教育、自动化初审和辅助判定的有效工具。未来作者拟探索多智能体协作加强Bug检测、支持任务分层与自我修正能力,并拓展跨更多语言和多样场景下的通用能力评测,以挖掘LLM在全球性软件可靠性保障中的更大潜能。
综上,这项工作不仅为LLM在代码安全、自动审查与程序修复领域的落地提供了科学依据,也为后续模型架构优化、提示协议演进和综合应用生态建设打下了坚实基础。
声明:本文来自安全极客,稿件和图片版权均归原作者所有。所涉观点不代表东方安全立场,转载目的在于传递更多信息。如有侵权,请联系rhliu@skdlabs.com,我们将及时按原作者或权利人的意愿予以更正。
- 以色列国防军禁止高级军官使用安卓手机,强制使用iPhone
- 《公安机关网络空间安全监督检查办法》草案与旧版对比
- 完整议程|12.10-11第二十届中国IDC产业年度大典北京·首钢园启动
- 赛可达实验室携手国际网安盛会,AVAR 2025即将开幕!
- AI全面渗透网络攻击!趋势科技发布2026年六大网络威胁预测
- 2025暴露面管理市场指南:现代风险与暴露面管理平台的演进
- SaaS安全大崩盘!又一起重大攻击,超200家大中型企业数据泄露
- 加紧突破低空智联网建设难题,保障低空运行安全
- 从“高可用”到“高韧性”:企业如何构建不“怕”故障的架构?
- Fortinet CISO预测2026年安全行业:AI重构攻防,CISO以弹性掌舵